
A Practical Guide to AI for Search
A Practical Guide to AI for Search
How we incorporated OpenAI vector embeddings to improve our search

We were feeling very inspired✨ by
’s new vector embedding, so we used it to overhaul’s Spillt's search functionality. I'm sharing a bit about how we did that (spoiler alert: VERY quickly, and with a lean team), as well as some of the more technical learnings that we’ve had so far.Background
For context, Supabase is our backend provider, similar to an open source Firebase, but using Postgres. When a Spillt user pastes in a recipe URL, we extract the metadata of the recipe (title, blog name, ingredients, thumbnail) and save it to Supabase in a table called recipes. Our users have imported over 80k recipes (!) into our database so far.
Another important feature to Spillt is our social graph – we encourage our users to follow their friends, and to see what they're cooking. That social graph is also stored on Supabase.
We're also a very lean team (just two of us full-time, and one very talented contract engineer – hence the need for “practicality” as mentioned in the title for this post). We knew we weren't going to compete with Google’s search capabilities from day one.
In the beginning we intentionally under-invested in search, starting with a very basic SQL string matching when you search for recipes (i.e. if you search for “chicken soup” we find exact matches to recipes with “chicken soup” in the title).

Our value was that we showed you recipes that you yourself had already saved, and also ones that your friends have saved, providing a meaningfully different experience from, say, Google.
Enter AI: we knew we wanted more flexibility, and realized with the changes made by Supabase that it would suddenly be very doable for a very generalist developer (myself!)
I also made the mistake of sending this very helpful video:
to my co-founder/sister, which resulted in the below series of texts.
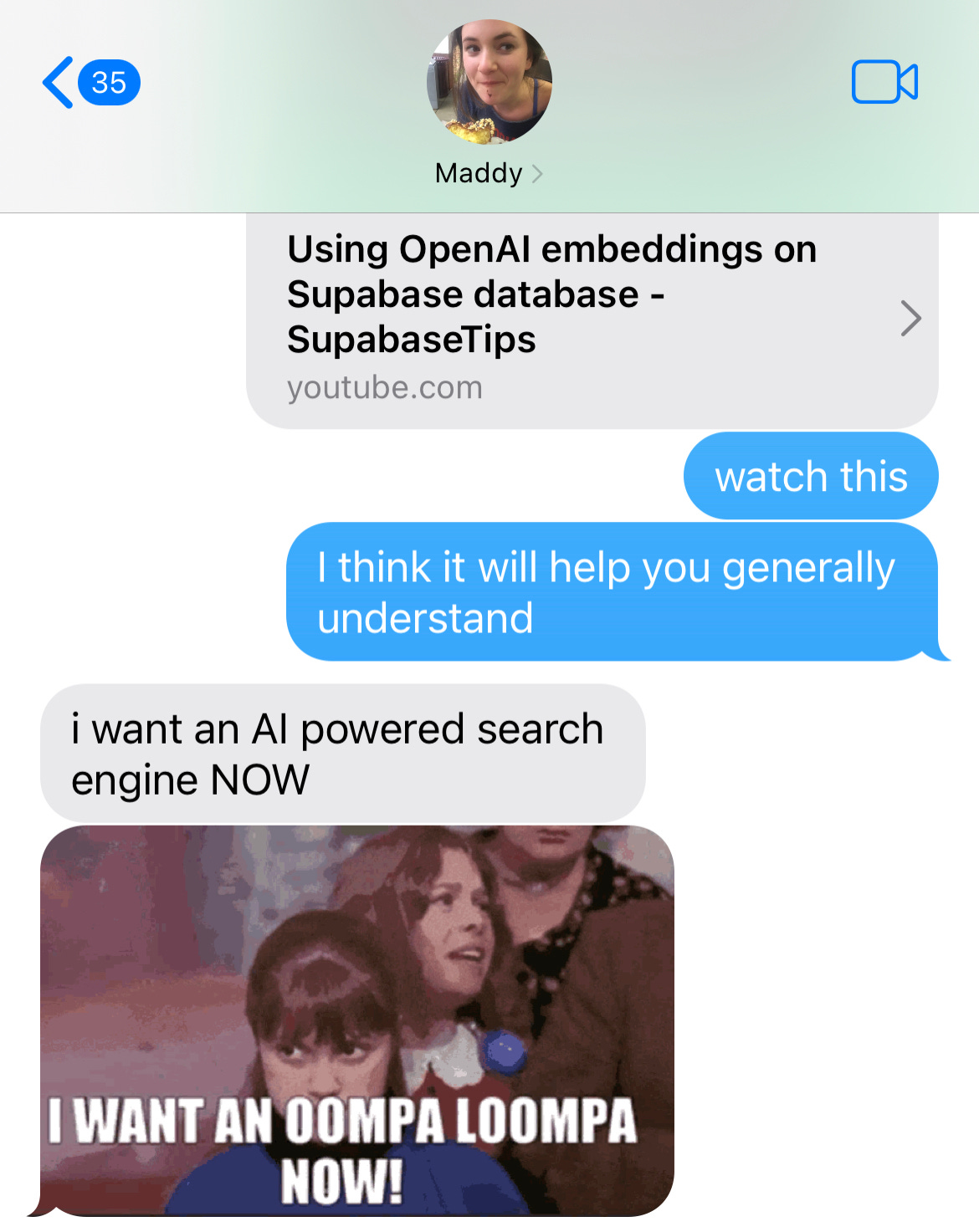
Our initial implementation
We followed roughly the tutorial outlined in the video, described below with a few modifications for our app:
I created a text representation (a JSON object) for each recipe including its title, blog name, and ingredients.
I used the Open AI embedding endpoint to generate a vector representation for each recipe, which I stored in a new
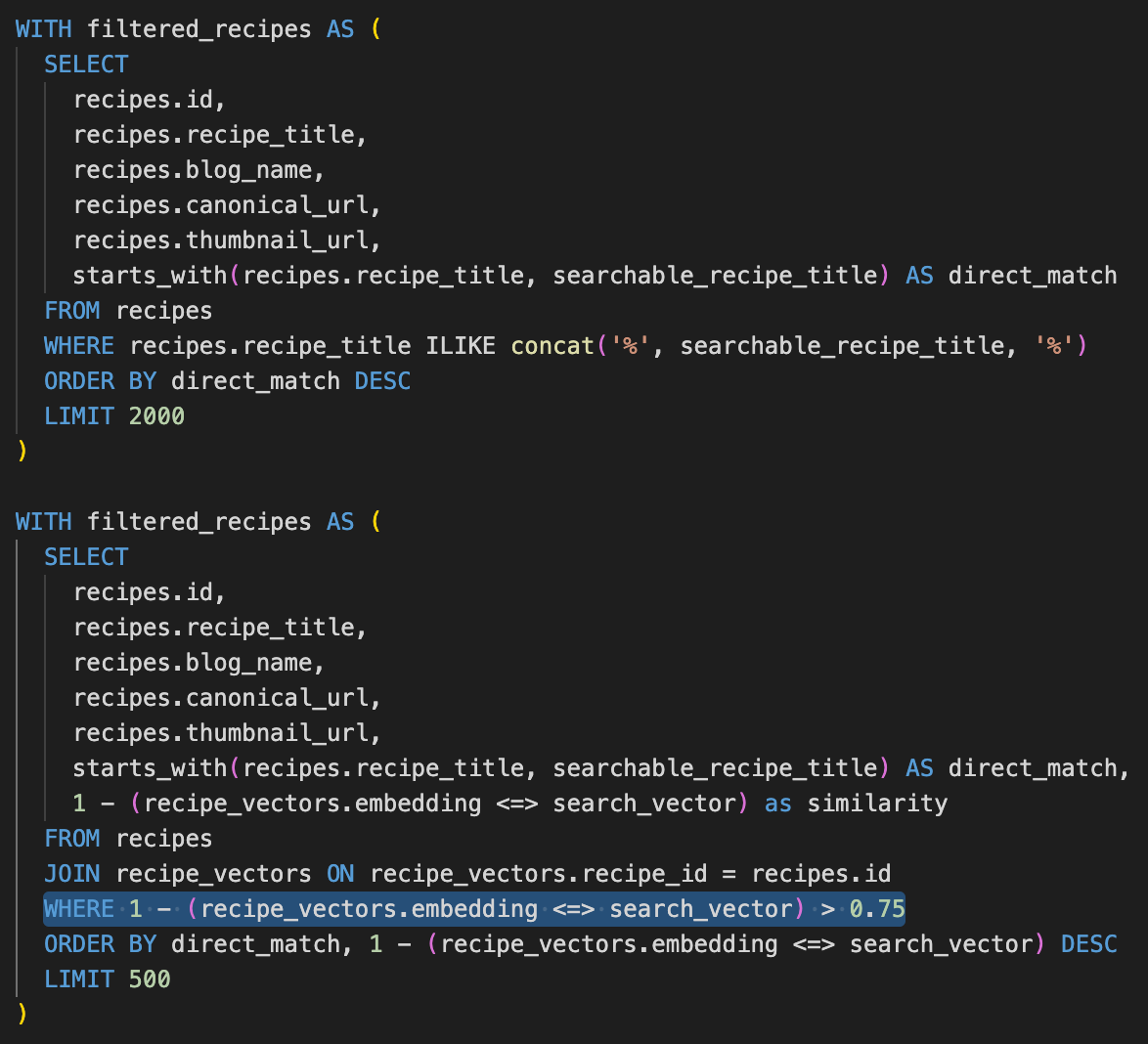
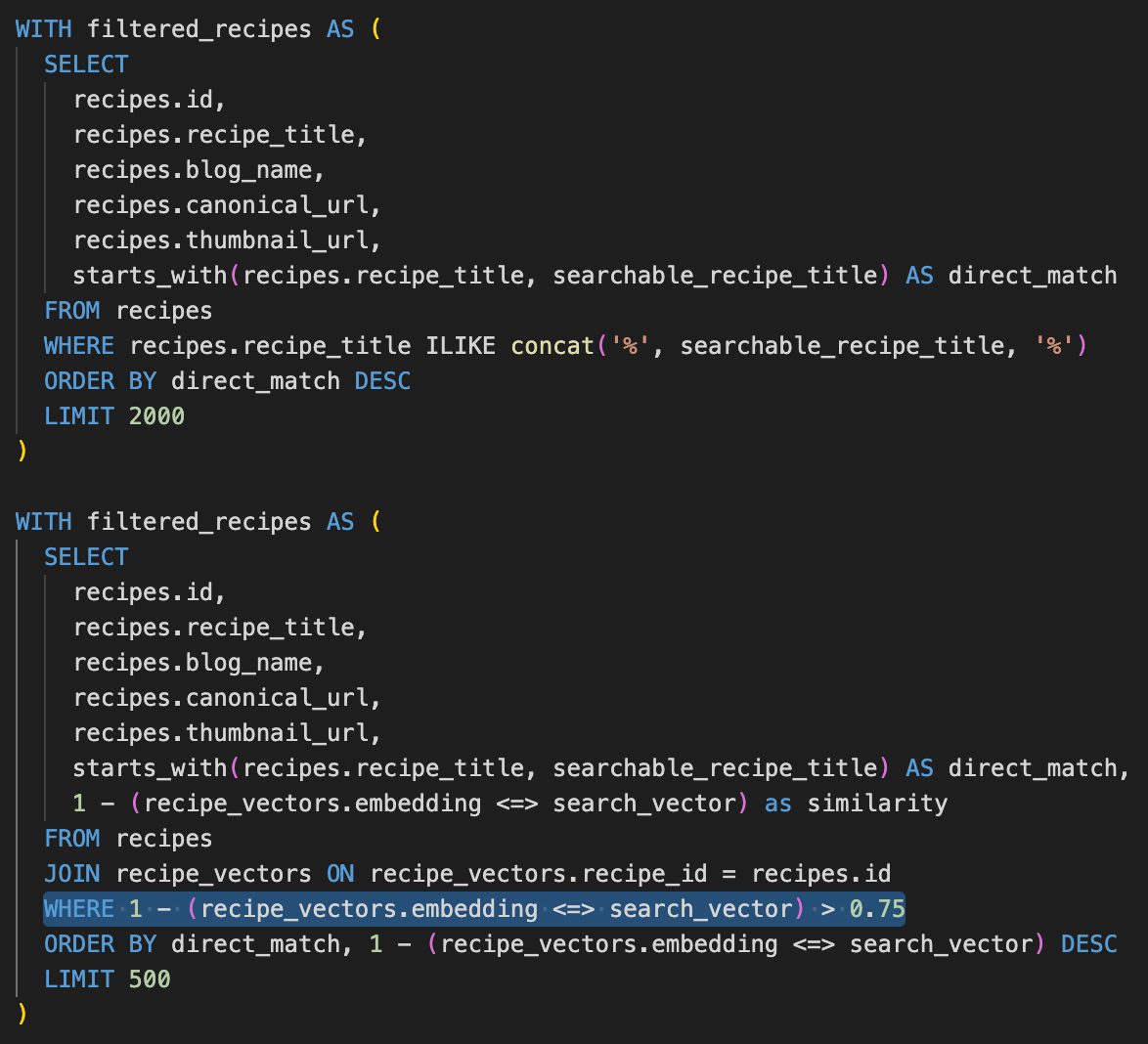
recipe_vectorstable along with the recipe's unique ID. Each vector representation is literally just a long list of numbers (1,536 long!)When we run a search from the app today, we send the search string to a Supabase Remote Procedure Call (RPC). That RPC filters all the recipes that match the search string exactly (limited to the first 2000), then sorts them to show you ones that you’ve saved, followed by the most popular ones and ones your friends have saved, and sends all the data back down to the app (in order). We modified that RPC with two changes:
First, we added logic to call the OpenAI embedding endpoint to get a vector representation of the query (e.g. “chicken soup”).
Notably, we saw from our data that a lot of our searches were the same things (“chicken”, “pasta”, “vegetarian”, etc.) so we save the search vector to a table called
search_query_vectorswhich helps avoid both financial and time expense of duplicative OpenAI API calls.Doing this request in Postgres took a little trial and error, so I have included the code in the appendix1 below on the small chance someone else pursues this approach (though I really would advise using an Edge function to avoid timeouts!)
Next, instead of a string match, we calculated the cosine distance function directly in the RPC to find the similarity score between each recipe and the search query vector, and surfaced the top 500 recipes, all matching above an arbitrary threshold of 0.75.
We initially left the same sorting mechanic in place, surfacing the recipes that you saved first, followed by ones that your friends have saved, and returning the ordered list to the client.
This was a very easy change to a subquery, shown below to highlight how straightforward it was!
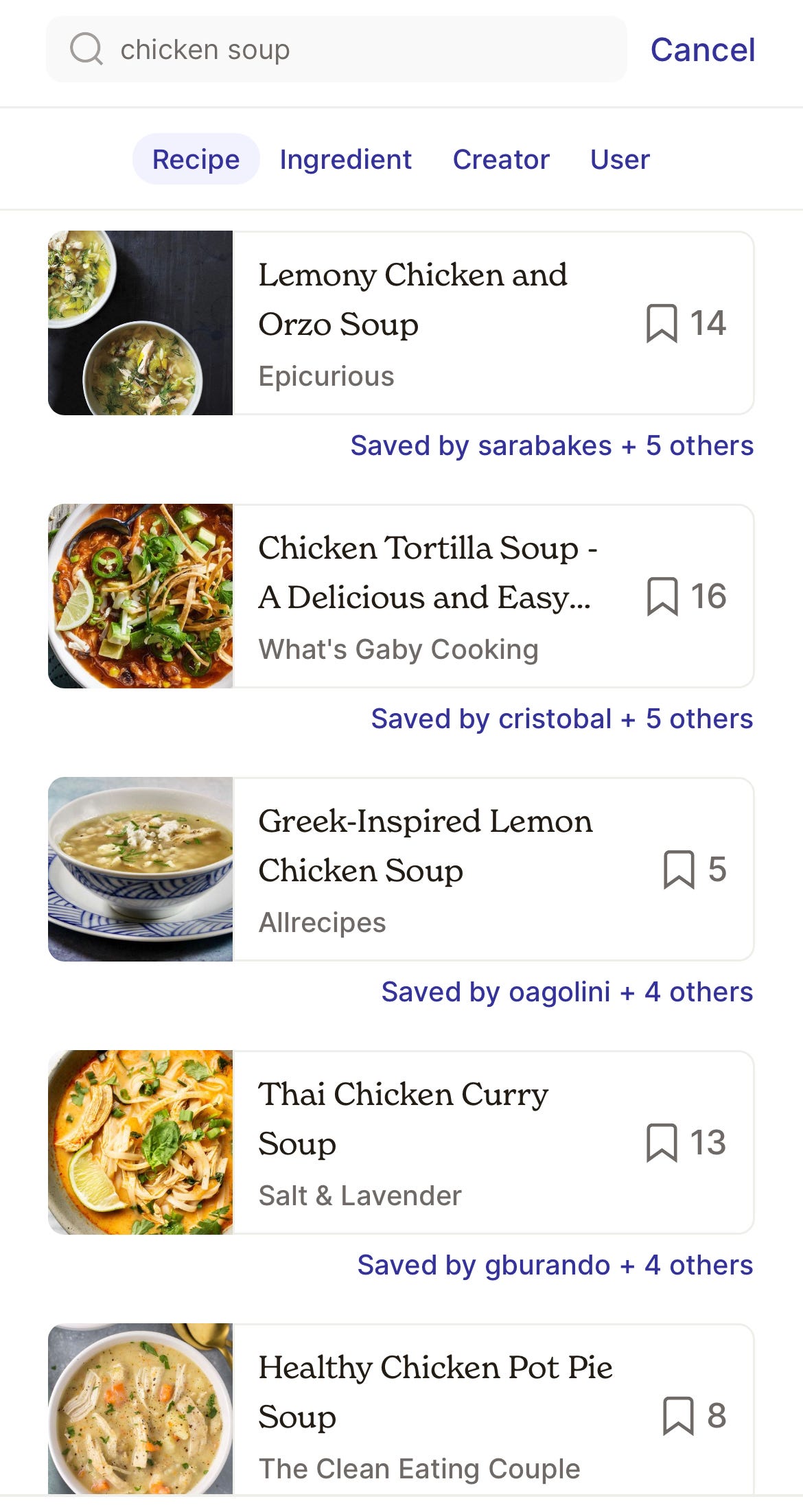
And… that was it! The coolest part of the whole experience was how quickly we went from Veruca Salt Maddy’s “I want AI now!” to a working prototype. The new search was a lot more forgiving if you, for example, forget whether a recipe is called “Cheesy Homemade Mac & Cheese” or “Homemade Cheesiest.” You can easily see the improvement in “chicken soup” results here:
The remaining work from a product and technical standpoint is as follows:
Increasing the data in recipe embeddings
Right now, we only extract a limited amount of data from recipes in order to display a preview in the app to users. However, we know the rich context provided by bloggers would help better inform the vector embeddings that we use to match user queries. We’re exploring adding more data to the JSON objects mentioned previously, and re-running the embeddings with the additional context.
We also think the additional context will help more complex queries, like “good sandwiches for a summer picnic” which require more nuance than simply the title and ingredients of a recipe.
Fine-tuning the search results
From analyzing our data, we noticed two distinct types of queries:
Browsing queries that were open-ended, for things like “chicken” or “vegan” or “pasta.” For these queries, there were a lot of good matches, so it was more helpful to see the ones that we had saved or our friends had saved.
Specific queries, like “tiramisu” or “cold-brew ice cream.” For these queries, it felt less helpful to see our friends’ activity, as we likely had a set of requirements in mind. We were looking for a “great” match.
Our rudimentary Postgres sorting had a hard time handling both these cases. We roughly quantified this by looking at the top 500 results for each query, and analyzing their vector similarity by plotting the median, standard deviation, and 99th percentile (indicated by the size of each bubble) as shown below.
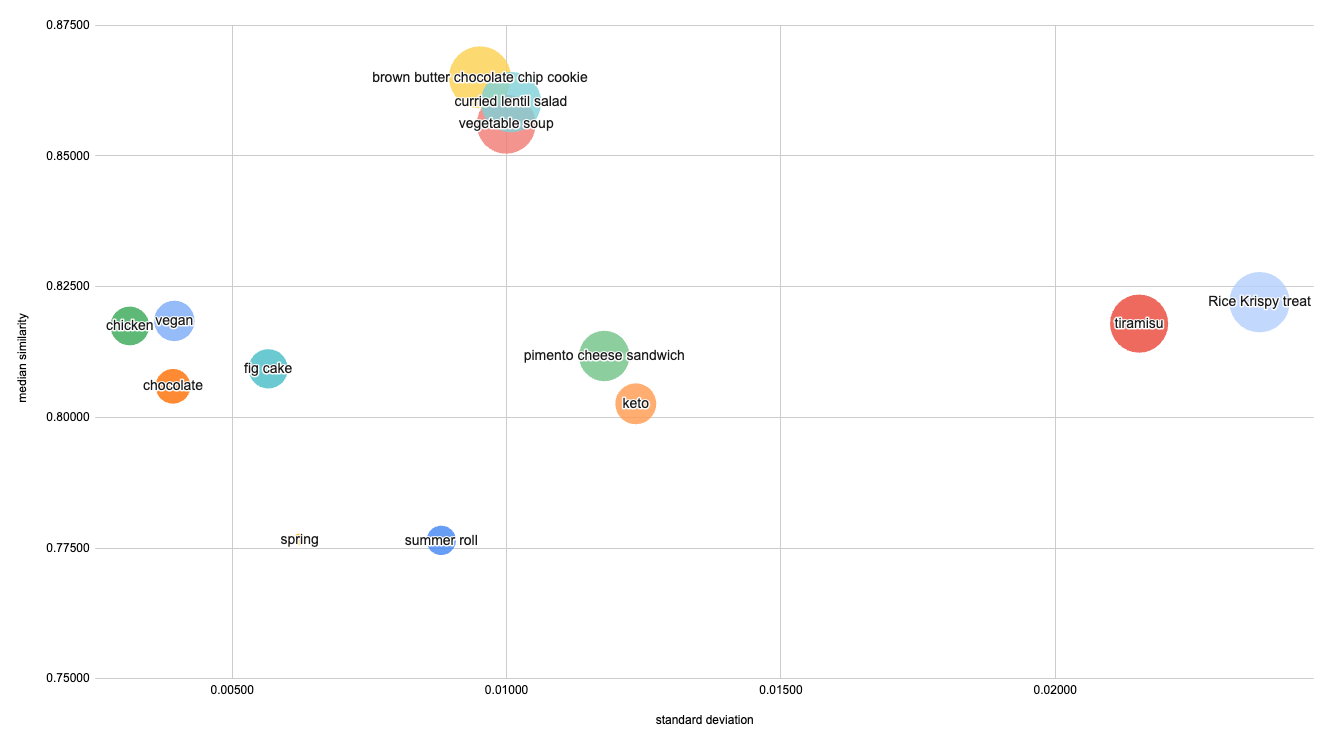
We had a lot of fun looking at this data, but one takeaway is that browsing queries had lower standard deviation but fewer great matches (lower P99), though this clearly varied across queries.
In our rudimentary implementation, we basically had to decide whether to give more weight to the similarity score, or more weight to the social context (whether a user had saved the recipe, or their friends had). When we over-weighted the social context, we saw strange behavior, like a “Fig Mascarpone Tart” showing up in results for “tiramisu” (both use mascarpone!) If we only weighted similarity, we found ourselves frustrated when scrolling through generic chicken recipes looking for inspiration.
Our blended metric tries to straddle those two factors, but we will continue to iterate on it as we get feedback (and improve the performance – more below!)
Production-izing the performance
The last steps are more technical in nature, but we continue to work on improving the performance by:
A recurring job to generate embeddings as new recipes are imported into the database. We have been burned by over-using Postgres triggers for network requests, and want to decouple the Postgres transaction of entering a recipe into the database from the OpenAI network request. To that end, we have a pg_cron job that looks for new recipes and generates the embedding periodically (every 15 minutes for now).
Indexing the recipe vector embeddings.
A consolidated Edge function for search queries. Doing a network request alongside an already expensive query occasionally timed out the Postgres RPC, which is why we would recommend using some cloud-based function instead with a bit more flexibility.
Known Limitations
Filters or restrictions As one example we found in testing, vegetarian soup sometimes still surfaced examples with chicken that happened to be vegetable heavy, as long as they matched our arbitrary threshold. Diet restrictions, like keto, were also hit or miss. We definitely recommend users exercise good judgment when assessing or selecting recipes that match important criteria!
Ignored modifiers We also found that words like “without” were often ignored. A search for “roast chicken without lemon” still surfaced… lots of lemons. This is still a work in progress, and we certainly plan to improve the functionality further.
In conclusion
This is all very much a work in progress! Download Spillt and let us know what you think. Or, if you’ve made it this far, please feel free to get in touch with any thoughts/suggestions/feedback.
Thanks for reading!
If you do need need to access the OpenAI API endpoint from Postgres, this is what we use:
SELECT ARRAY(
SELECT json_array_elements_text(((content::json->>'data')::json)->0->'embedding')::float8
FROM http((
'POST',
'https://api.openai.com/v1/embeddings',
ARRAY[http_header('Authorization', 'Bearer OPEN_AI_KEY')],
'application/json',
json_build_object('input', LOWER(searchable_recipe_title), 'model', 'text-embedding-ada-002')
)::http_request)
)::vector INTO search_vector;
This was informative! Since you implemented it, does the cost make sense? Without AI, you would've had exact matches, but, not flexible. I've notice, as you have too, that the results are better, with a slight accuracy degradation.
That was a great read! Super cool to see how you’re incorporating things.